-
Type:
Bug
-
Resolution: Fixed
-
Priority:
 Major
Major
-
Component/s: amazon-ecs-plugin
-
None
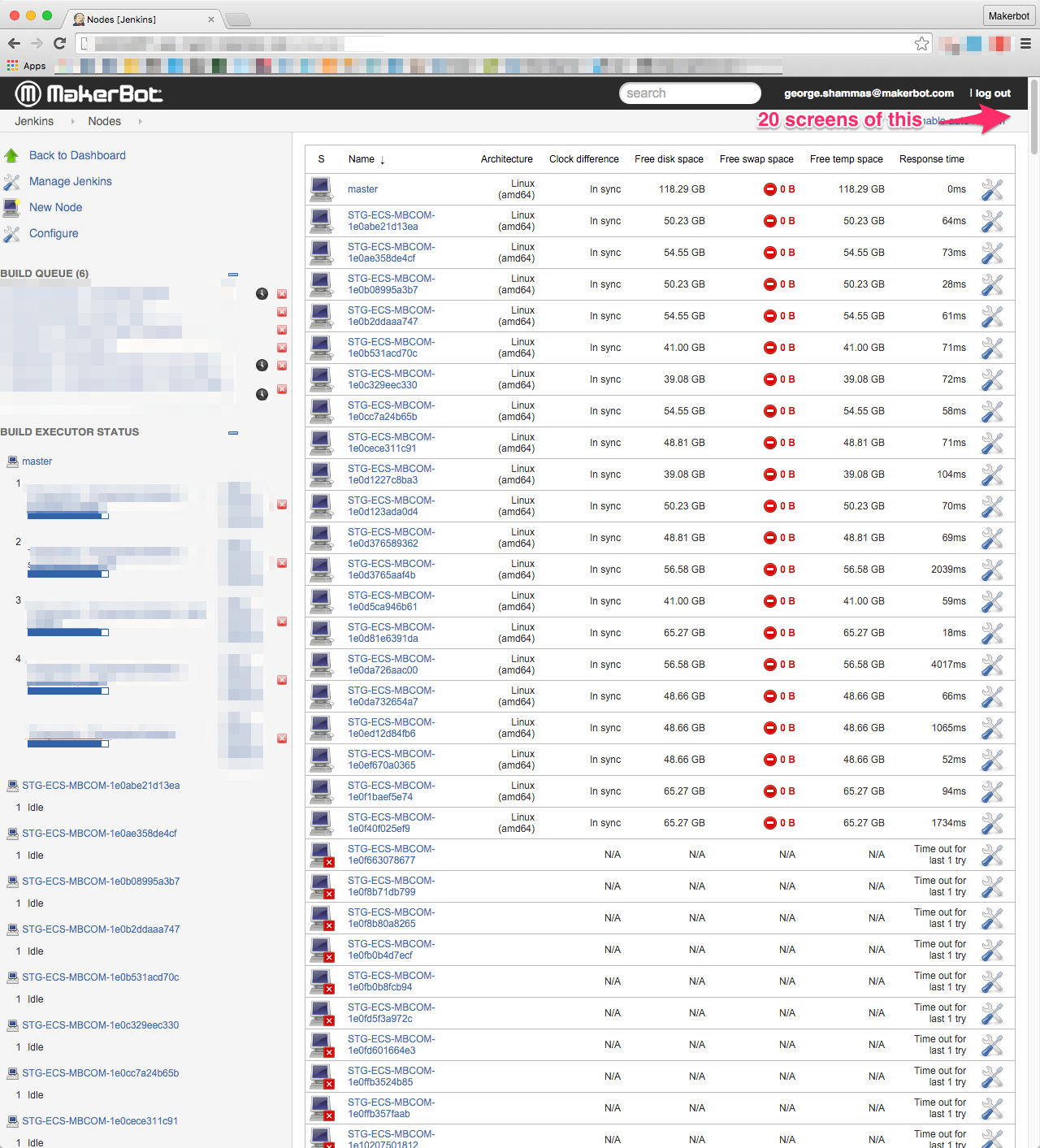
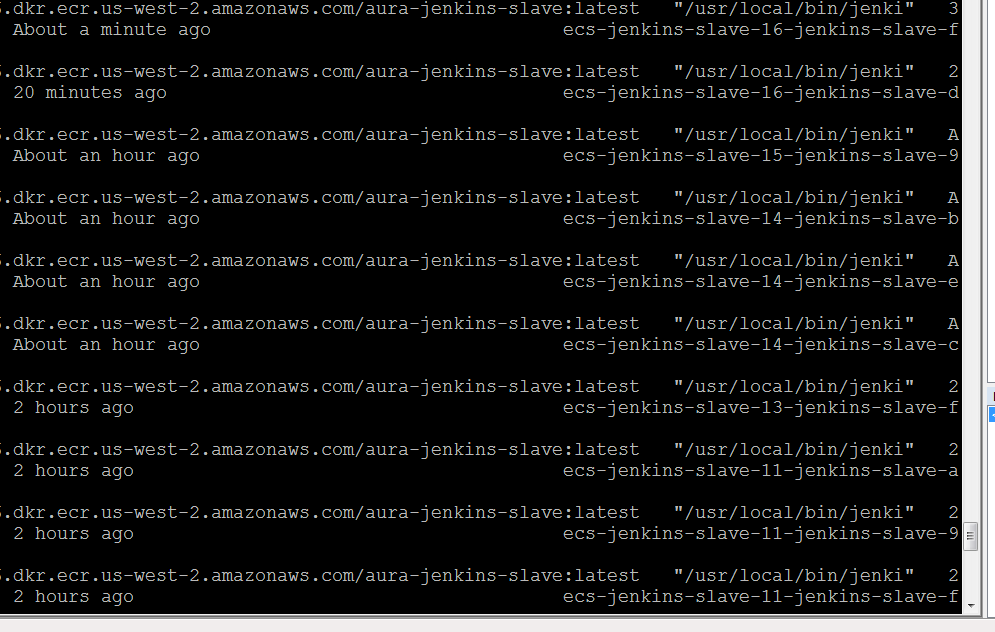
When the local job queue fills on the master, this plugin will start spinning up slaves. However, if those jobs have a restriction on where they can run, they will never be scheduled on those slaves.
As a result with 4 threads on the master, and 6 jobs, this will spin up hundreds slaves. The ECS cluster on has capacity for about 30 of those, so they never actually spin up, creating a mess out of the node list for a while.
Attached is an example of what this looks like. All the jobs scheduled have a restriction of running on the master, because they are building docker containers.

{kind=link}
{kind=link}