-
Type:
Bug
-
Resolution: Cannot Reproduce
-
Priority:
 Major
Major
-
Component/s: swarm-plugin
-
None
-
Environment:Jenkins: 2.492.2
OS: Linux - 5.15.0-133-generic
Java: 21.0.6 - Eclipse Adoptium (OpenJDK 64-Bit Server VM)
---
active-directory:2.39
ansicolor:1.0.6
ant:513.vde9e7b_a_0da_0f
antisamy-markup-formatter:173.v680e3a_b_69ff3
apache-httpcomponents-client-4-api:4.5.14-269.vfa_2321039a_83
apache-httpcomponents-client-5-api:5.4-136.v5a_21779c63f8
artifactory:4.0.8
asm-api:9.7.1-97.v4cc844130d97
atlassian-bitbucket-server-integration:4.1.4
authentication-tokens:1.131.v7199556c3004
bitbucket:263.v7f6ef03c9ef8
blueocean:1.27.17
blueocean-bitbucket-pipeline:1.27.17
blueocean-commons:1.27.17
blueocean-config:1.27.17
blueocean-core-js:1.27.17
blueocean-dashboard:1.27.17
blueocean-display-url:2.4.4
blueocean-events:1.27.17
blueocean-git-pipeline:1.27.17
blueocean-github-pipeline:1.27.17
blueocean-i18n:1.27.17
blueocean-jwt:1.27.17
blueocean-personalization:1.27.17
blueocean-pipeline-api-impl:1.27.17
blueocean-pipeline-editor:1.27.17
blueocean-pipeline-scm-api:1.27.17
blueocean-rest:1.27.17
blueocean-rest-impl:1.27.17
blueocean-web:1.27.17
bootstrap5-api:5.3.3-2
bouncycastle-api:2.30.1.80-256.vf98926042a_9b_
branch-api:2.1214.v3f652804588d
build-failure-analyzer:2.5.4
build-monitor-plugin:1.14-961.v676e38a_7a_248
build-timestamp:1.1.0
build-with-parameters:76.v9382db_f78962
caffeine-api:3.2.0-161.v691ef352cee1
checks-api:367.v18b_7f530e54a_
cloud-stats:377.vd8a_6c953e98e
cloudbees-bitbucket-branch-source:935.1.1
cloudbees-folder:6.985.va_f1635030cc5
command-launcher:116.vd85919c54a_d6
commons-compress-api:1.27.1-2
commons-lang3-api:3.17.0-84.vb_b_938040b_078
commons-text-api:1.13.0-153.v91dcd89e2a_22
config-file-provider:982.vb_a_e458a_37021
configuration-as-code:1932.v75cb_b_f1b_698d
credentials:1408.va_622a_b_f5b_1b_1
credentials-binding:687.v619cb_15e923f
dark-theme:524.vd675b_22b_30cb_
data-tables-api:2.2.2-1
display-url-api:2.209.v582ed814ff2f
docker-commons:445.v6b_646c962a_94
docker-java-api:3.4.1-96.v77147a_de67f8
docker-plugin:1.10.0
downstream-build-cache:1.7
dtkit-api:3.0.3
durable-task:587.v84b_877235b_45
dynamic_extended_choice_parameter:1.0.1
echarts-api:5.6.0-2
eddsa-api:0.3.0-13.v7cb_69ed68f00
embeddable-build-status:548.v5653c6e28c41
extended-choice-parameter:388.ve7b_d0b_920e10
favorite:2.225.v68765b_b_a_1fa_3
font-awesome-api:6.7.2-1
git:5.7.0
git-client:6.1.2
github:1.42.0
github-api:1.321-478.vc9ce627ce001
github-branch-source:1810.v913311241fa_9
gradle:2.14.1
gson-api:2.12.1-113.v347686d6729f
handy-uri-templates-2-api:2.1.8-36.v85e4cb_234a_13
hidden-parameter:414.vfe0a_8b_052546
htmlpublisher:424.va_e57f1253461
influxdb:4.0
instance-identity:203.v15e81a_1b_7a_38
ionicons-api:82.v0597178874e1
jackson2-api:2.18.3-399.v74c9ce452ea_8
jakarta-activation-api:2.1.3-2
jakarta-mail-api:2.1.3-2
javadoc:310.v032f3f16b_0f8
javax-activation-api:1.2.0-8
javax-mail-api:1.6.2-10
jaxb:2.3.9-133.vb_ec76a_73f706
jdk-tool:80.v8a_dee33ed6f0
jenkins-design-language:1.27.17
jersey2-api:2.45-154.v4ded3dc34f81
jjwt-api:0.11.5-120.v0268cf544b_89
joda-time-api:2.13.1-115.va_6b_5f8efb_1d8
jquery3-api:3.7.1-3
jsch:0.2.16-95.v3eecb_55fa_b_78
json-api:20250107-125.v28b_a_ffa_eb_f01
json-path-api:2.9.0-148.v22a_7ffe323ce
junit:1317.v5b_35d792b_06a_
leastload:62.vfa_8830902733
lockable-resources:1349.v8b_ccb_c5487f7
log-file-filter:119.vef6c84f663c7
mailer:489.vd4b_25144138f
mapdb-api:1.0.9-44.va_1e1310c9118
mask-passwords:188.v66e477dcb_24a_
matrix-auth:3.2.4
matrix-project:845.vffd7fa_f27555
maven-plugin:3.25
mercurial:1309.v6802b_f0efb_b_9
metrics:4.2.21-464.vc9fa_a_0d6265d
mina-sshd-api-common:2.14.0-143.v2b_362fc39576
mina-sshd-api-core:2.14.0-143.v2b_362fc39576
okhttp-api:4.11.0-183.va_87fc7a_89810
oss-symbols-api:308.v0c48656b_15c1
pipeline-as-yaml:270.vc348a_45d9214
pipeline-build-step:557.v95d96f77b_2b_8
pipeline-graph-analysis:231.v56354571a_da_0
pipeline-groovy-lib:752.vdddedf804e72
pipeline-input-step:517.vf8e782ee645c
pipeline-milestone-step:127.vb_52887ca_3b_6d
pipeline-model-api:2.2247.va_423189a_7dff
pipeline-model-definition:2.2247.va_423189a_7dff
pipeline-model-extensions:2.2247.va_423189a_7dff
pipeline-rest-api:2.37
pipeline-stage-step:322.vecffa_99f371c
pipeline-stage-tags-metadata:2.2247.va_423189a_7dff
pipeline-stage-view:2.37
pipeline-utility-steps:2.19.0
plain-credentials:183.va_de8f1dd5a_2b_
plugin-util-api:6.0.0
prism-api:1.29.0-19
prometheus:819.v50953a_c560dd
pubsub-light:1.19
rebuild:338.va_0a_b_50e29397
resource-disposer:0.25
role-strategy:756.v978cb_392eb_d3
scm-api:704.v3ce5c542825a_
script-security:1373.vb_b_4a_a_c26fa_00
simple-theme-plugin:202.v6367d3dea_73b_
snakeyaml-api:2.3-123.v13484c65210a_
sse-gateway:1.28
ssh-credentials:355.v9b_e5b_cde5003
ssh-slaves:3.1031.v72c6b_883b_869
sshd:3.330.vc866a_8389b_58
structs:343.vdcf37b_a_c81d5
subversion:1287.vd2d507146906
swarm:3.49
theme-manager:278.v2e3c063e42cc
timestamper:1.28
token-macro:444.v52de7e9c573d
trilead-api:2.192.vc50a_d147e369
uno-choice:2.8.6
variant:70.va_d9f17f859e0
workflow-api:1363.v03f731255494
workflow-basic-steps:1079.vce64b_a_929c5a_
workflow-cps:4043.va_fb_de6a_a_8b_f5
workflow-durable-task-step:1405.v1fcd4a_d00096
workflow-job:1505.vea_4b_20a_4a_495
workflow-multibranch:803.v08103b_87c280
workflow-scm-step:437.v05a_f66b_e5ef8
workflow-step-api:700.v6e45cb_a_5a_a_21
workflow-support:961.v51869f7b_d409
ws-cleanup:0.48
xunit:3.1.5
yet-another-build-visualizer:1.17
---
ENV variables:
"JAVA_OPTS=-XX:+UseG1GC -Xms16g -Xmx16g -XX:+AlwaysPreTouch -XX:+UseStringDeduplication -XX:+DisableExplicitGC -XX:+ParallelRefProcEnabled -Dhudson.model.ParametersAction.keepUndefinedParameters=true\n -Dorg.jenkinsci.plugins.durabletask.BourneShellScript.HEARTBEAT_CHECK_INTERVAL=300 -agentpath:/usr/local/yourkit/bin/linux-x86-64/libyjpagent.so=port=10001,listen=all -Dhudson.model.Run.ArtifactList.listCutoff=5 -Dhudson.model.Run.ArtifactList.treeCutoff=120",
JAVA_OPTS="-agentpath:/usr/local/yourkit/bin/linux-x86-64/libyjpagent.so=port=10001,listen=all",Jenkins: 2.492.2 OS: Linux - 5.15.0-133-generic Java: 21.0.6 - Eclipse Adoptium (OpenJDK 64-Bit Server VM) --- active-directory:2.39 ansicolor:1.0.6 ant:513.vde9e7b_a_0da_0f antisamy-markup-formatter:173.v680e3a_b_69ff3 apache-httpcomponents-client-4-api:4.5.14-269.vfa_2321039a_83 apache-httpcomponents-client-5-api:5.4-136.v5a_21779c63f8 artifactory:4.0.8 asm-api:9.7.1-97.v4cc844130d97 atlassian-bitbucket-server-integration:4.1.4 authentication-tokens:1.131.v7199556c3004 bitbucket:263.v7f6ef03c9ef8 blueocean:1.27.17 blueocean-bitbucket-pipeline:1.27.17 blueocean-commons:1.27.17 blueocean-config:1.27.17 blueocean-core-js:1.27.17 blueocean-dashboard:1.27.17 blueocean-display-url:2.4.4 blueocean-events:1.27.17 blueocean-git-pipeline:1.27.17 blueocean-github-pipeline:1.27.17 blueocean-i18n:1.27.17 blueocean-jwt:1.27.17 blueocean-personalization:1.27.17 blueocean-pipeline-api-impl:1.27.17 blueocean-pipeline-editor:1.27.17 blueocean-pipeline-scm-api:1.27.17 blueocean-rest:1.27.17 blueocean-rest-impl:1.27.17 blueocean-web:1.27.17 bootstrap5-api:5.3.3-2 bouncycastle-api:2.30.1.80-256.vf98926042a_9b_ branch-api:2.1214.v3f652804588d build-failure-analyzer:2.5.4 build-monitor-plugin:1.14-961.v676e38a_7a_248 build-timestamp:1.1.0 build-with-parameters:76.v9382db_f78962 caffeine-api:3.2.0-161.v691ef352cee1 checks-api:367.v18b_7f530e54a_ cloud-stats:377.vd8a_6c953e98e cloudbees-bitbucket-branch-source:935.1.1 cloudbees-folder:6.985.va_f1635030cc5 command-launcher:116.vd85919c54a_d6 commons-compress-api:1.27.1-2 commons-lang3-api:3.17.0-84.vb_b_938040b_078 commons-text-api:1.13.0-153.v91dcd89e2a_22 config-file-provider:982.vb_a_e458a_37021 configuration-as-code:1932.v75cb_b_f1b_698d credentials:1408.va_622a_b_f5b_1b_1 credentials-binding:687.v619cb_15e923f dark-theme:524.vd675b_22b_30cb_ data-tables-api:2.2.2-1 display-url-api:2.209.v582ed814ff2f docker-commons:445.v6b_646c962a_94 docker-java-api:3.4.1-96.v77147a_de67f8 docker-plugin:1.10.0 downstream-build-cache:1.7 dtkit-api:3.0.3 durable-task:587.v84b_877235b_45 dynamic_extended_choice_parameter:1.0.1 echarts-api:5.6.0-2 eddsa-api:0.3.0-13.v7cb_69ed68f00 embeddable-build-status:548.v5653c6e28c41 extended-choice-parameter:388.ve7b_d0b_920e10 favorite:2.225.v68765b_b_a_1fa_3 font-awesome-api:6.7.2-1 git:5.7.0 git-client:6.1.2 github:1.42.0 github-api:1.321-478.vc9ce627ce001 github-branch-source:1810.v913311241fa_9 gradle:2.14.1 gson-api:2.12.1-113.v347686d6729f handy-uri-templates-2-api:2.1.8-36.v85e4cb_234a_13 hidden-parameter:414.vfe0a_8b_052546 htmlpublisher:424.va_e57f1253461 influxdb:4.0 instance-identity:203.v15e81a_1b_7a_38 ionicons-api:82.v0597178874e1 jackson2-api:2.18.3-399.v74c9ce452ea_8 jakarta-activation-api:2.1.3-2 jakarta-mail-api:2.1.3-2 javadoc:310.v032f3f16b_0f8 javax-activation-api:1.2.0-8 javax-mail-api:1.6.2-10 jaxb:2.3.9-133.vb_ec76a_73f706 jdk-tool:80.v8a_dee33ed6f0 jenkins-design-language:1.27.17 jersey2-api:2.45-154.v4ded3dc34f81 jjwt-api:0.11.5-120.v0268cf544b_89 joda-time-api:2.13.1-115.va_6b_5f8efb_1d8 jquery3-api:3.7.1-3 jsch:0.2.16-95.v3eecb_55fa_b_78 json-api:20250107-125.v28b_a_ffa_eb_f01 json-path-api:2.9.0-148.v22a_7ffe323ce junit:1317.v5b_35d792b_06a_ leastload:62.vfa_8830902733 lockable-resources:1349.v8b_ccb_c5487f7 log-file-filter:119.vef6c84f663c7 mailer:489.vd4b_25144138f mapdb-api:1.0.9-44.va_1e1310c9118 mask-passwords:188.v66e477dcb_24a_ matrix-auth:3.2.4 matrix-project:845.vffd7fa_f27555 maven-plugin:3.25 mercurial:1309.v6802b_f0efb_b_9 metrics:4.2.21-464.vc9fa_a_0d6265d mina-sshd-api-common:2.14.0-143.v2b_362fc39576 mina-sshd-api-core:2.14.0-143.v2b_362fc39576 okhttp-api:4.11.0-183.va_87fc7a_89810 oss-symbols-api:308.v0c48656b_15c1 pipeline-as-yaml:270.vc348a_45d9214 pipeline-build-step:557.v95d96f77b_2b_8 pipeline-graph-analysis:231.v56354571a_da_0 pipeline-groovy-lib:752.vdddedf804e72 pipeline-input-step:517.vf8e782ee645c pipeline-milestone-step:127.vb_52887ca_3b_6d pipeline-model-api:2.2247.va_423189a_7dff pipeline-model-definition:2.2247.va_423189a_7dff pipeline-model-extensions:2.2247.va_423189a_7dff pipeline-rest-api:2.37 pipeline-stage-step:322.vecffa_99f371c pipeline-stage-tags-metadata:2.2247.va_423189a_7dff pipeline-stage-view:2.37 pipeline-utility-steps:2.19.0 plain-credentials:183.va_de8f1dd5a_2b_ plugin-util-api:6.0.0 prism-api:1.29.0-19 prometheus:819.v50953a_c560dd pubsub-light:1.19 rebuild:338.va_0a_b_50e29397 resource-disposer:0.25 role-strategy:756.v978cb_392eb_d3 scm-api:704.v3ce5c542825a_ script-security:1373.vb_b_4a_a_c26fa_00 simple-theme-plugin:202.v6367d3dea_73b_ snakeyaml-api:2.3-123.v13484c65210a_ sse-gateway:1.28 ssh-credentials:355.v9b_e5b_cde5003 ssh-slaves:3.1031.v72c6b_883b_869 sshd:3.330.vc866a_8389b_58 structs:343.vdcf37b_a_c81d5 subversion:1287.vd2d507146906 swarm:3.49 theme-manager:278.v2e3c063e42cc timestamper:1.28 token-macro:444.v52de7e9c573d trilead-api:2.192.vc50a_d147e369 uno-choice:2.8.6 variant:70.va_d9f17f859e0 workflow-api:1363.v03f731255494 workflow-basic-steps:1079.vce64b_a_929c5a_ workflow-cps:4043.va_fb_de6a_a_8b_f5 workflow-durable-task-step:1405.v1fcd4a_d00096 workflow-job:1505.vea_4b_20a_4a_495 workflow-multibranch:803.v08103b_87c280 workflow-scm-step:437.v05a_f66b_e5ef8 workflow-step-api:700.v6e45cb_a_5a_a_21 workflow-support:961.v51869f7b_d409 ws-cleanup:0.48 xunit:3.1.5 yet-another-build-visualizer:1.17 --- ENV variables: "JAVA_OPTS=-XX:+UseG1GC -Xms16g -Xmx16g -XX:+AlwaysPreTouch -XX:+UseStringDeduplication -XX:+DisableExplicitGC -XX:+ParallelRefProcEnabled -Dhudson.model.ParametersAction.keepUndefinedParameters=true\n -Dorg.jenkinsci.plugins.durabletask.BourneShellScript.HEARTBEAT_CHECK_INTERVAL=300 -agentpath:/usr/local/yourkit/bin/linux-x86-64/libyjpagent.so=port=10001,listen=all -Dhudson.model.Run.ArtifactList.listCutoff=5 -Dhudson.model.Run.ArtifactList.treeCutoff=120", JAVA_OPTS="-agentpath:/usr/local/yourkit/bin/linux-x86-64/libyjpagent.so=port=10001,listen=all",
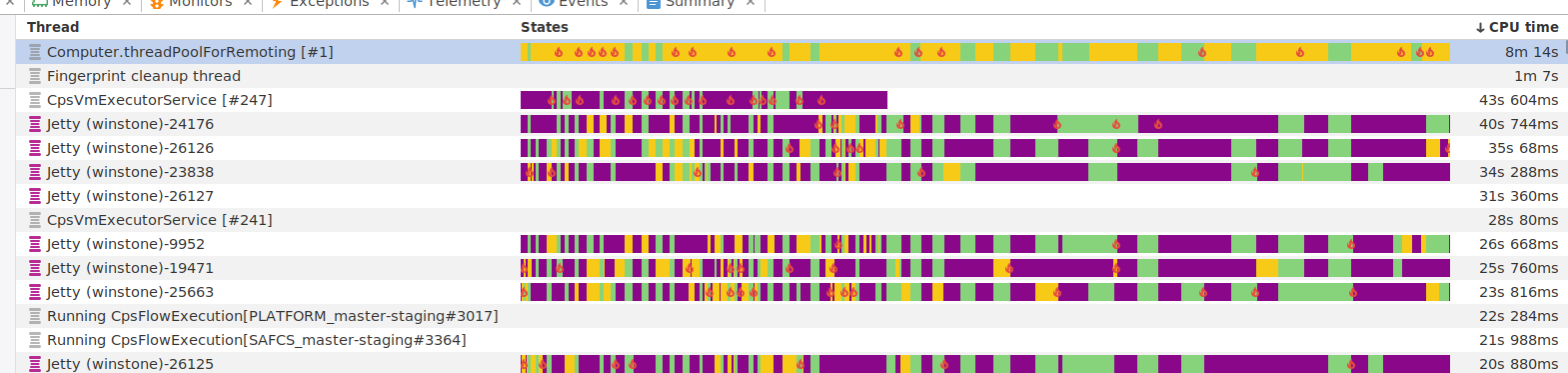
We are having major issues with our Jenkins instances and are trying to understand what the issue is. We currently have uptime of less than 2 days before the Jenkins docker we are running needs to be rebooted. We currently have ~10 build nodes connected to Jenkins with the Swarm plugin.
We can see that one thread seems to take all cpu-power of a single core when this happens. When profiling we can see that the Computer.threadPoolForRemoting thread seems to work continously. During this period the Web gui is incredibly slow and we may look at load times of multiple minutes for each page. The jobs that are scheduled and manually triggered keeps queuing up on the Built-in node and can not be handed over to the build agents fast enough. The connections to the agents are also very shaky and we get reconnection messages in the build logs.
I can see old issues (from 2015 to 2017) about the SSH agent leaking threads in Computer.threadPoolForRemoting. But it seems to have been resolved a log time ago. Have similar issues been known to exist in the Swarm plugin?
More about the environment:
Jenkins is running in a docker container based on jenkins/jenkins:jdk21, with the swarm-agent and the YourKit profiler agent added to it.
The host machine is a Virtual computer hosted in VCenter with 16 CPUs and 32GB RAM. The swarm agents are a mix of physical and virtual nodes but the specs of the 5 physical nodes we use are: 64 CPU, 1.5TB RAM, 4.0TB disk. The other nodes are virtual hosts with 8 CPUS and 16 GB RAM.
The total amount of jobs we start on these nodes are probably around 500 per day.
We have been following along with the releases of new Jenkins version for 3+ years and we have during this time never had a Jenkins controller that has "survived" for 3 weeks. During the last year we have had a scheduled docker restart every week and that has been sufficient until recently, when we got the issues described above, after just a couple of days.
What we have tried:
Restarting the jenkins docker container seems to "fix" the issue, but it only holds for ~2 days at the moment. We have also tried to disconnect the agents. We saw no difference in the jenkins CPU usage until the last agent had been disconnected. Then it went back to normal.