-
Type:
Bug
-
Resolution: Incomplete
-
Priority:
 Critical
Critical
-
Component/s: mercurial-plugin
-
Environment:Jenkins 2.26
We're attempting to configure a pipeline multibranch folder such that 'default' is always built but feature branches are only built daily. We did this by suppressing automatic SCM triggering for all branches except 'default', then configuring a separate pollSCM in the jenkinsfile for each branch.
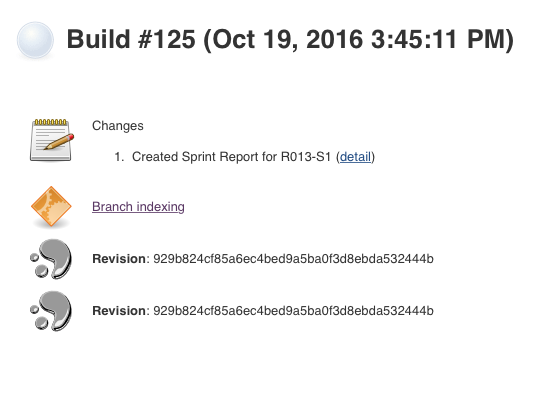
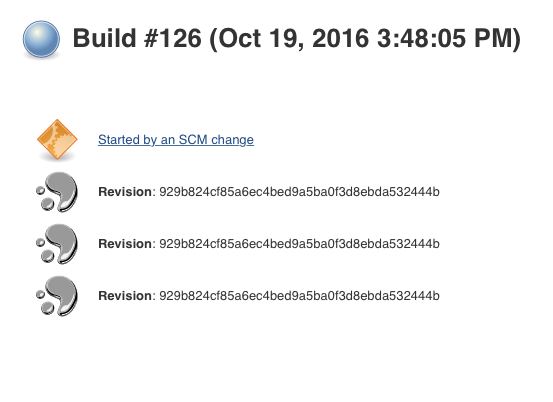
However we're seeing issues where feature branches that have changes are not built for days while sometimes a branch will be triggered many times for the same changeset.
Multiple jobs for the same changeset are triggered. The first by "Branch indexing" and the later ones by "Started by an SCM change". The logs show "Dependent changes detected"
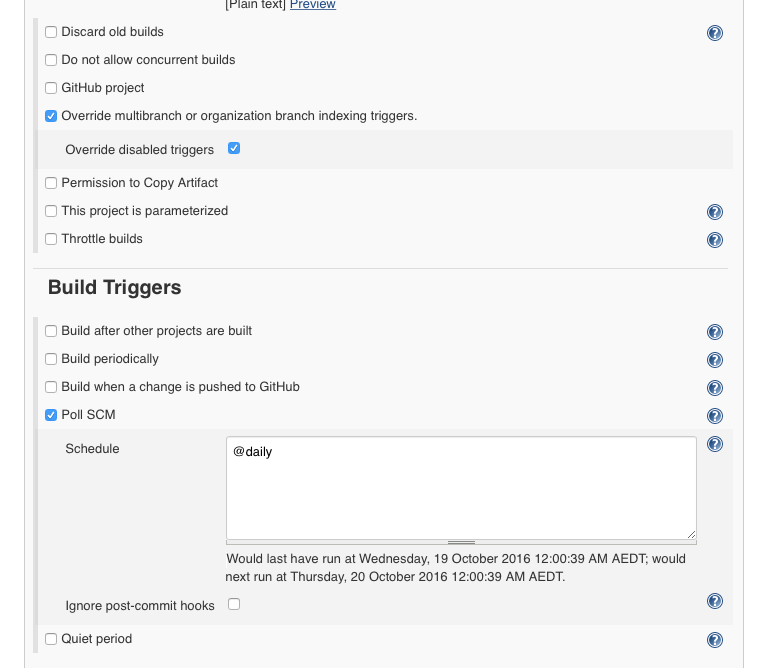
No other polling is configured.
Removing the pipelineTriggers/pollSCM property seems to stop repeat builds (but won't give you daily builds)
Our Jenkinsfile starts with this:
def alwaysBuild = (env.BRANCH_NAME == "default" || env.BRANCH_NAME ==~ /CompanyName-.*/);
properties([overrideIndexTriggers(alwaysBuild), pipelineTriggers([pollSCM('@daily')])]);
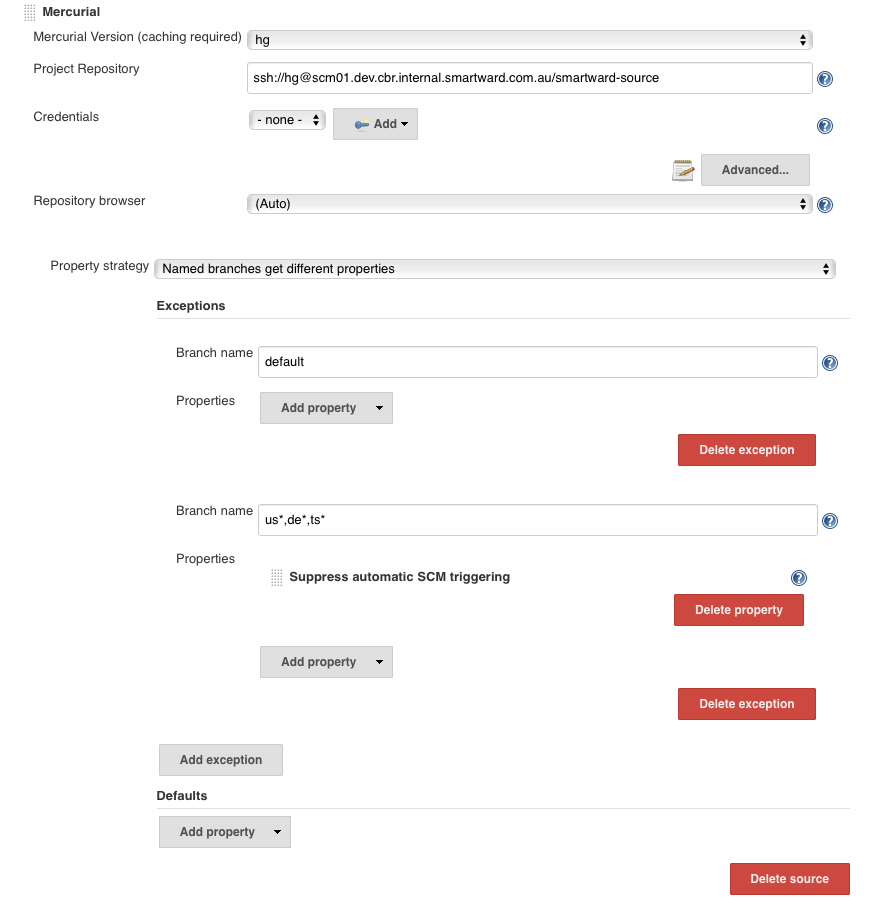
Multibranch folder is configured with properties overrides:
- "named branches get different properties"
exceptions:
"default": no properties
"us*,d*,ts*": Suppess automatic SCM triggering.
And every commit will notify jenkins via
curl -v http://jenkins:8080/mercurial/notifyCommit?url=ssh://hg@scm01/sw-source
- is related to
-
-
- Reopened
-
